CVPR 2026
Multi-view Consistent 3D Gaussian Head Avatars 'without' Multi-view Generation
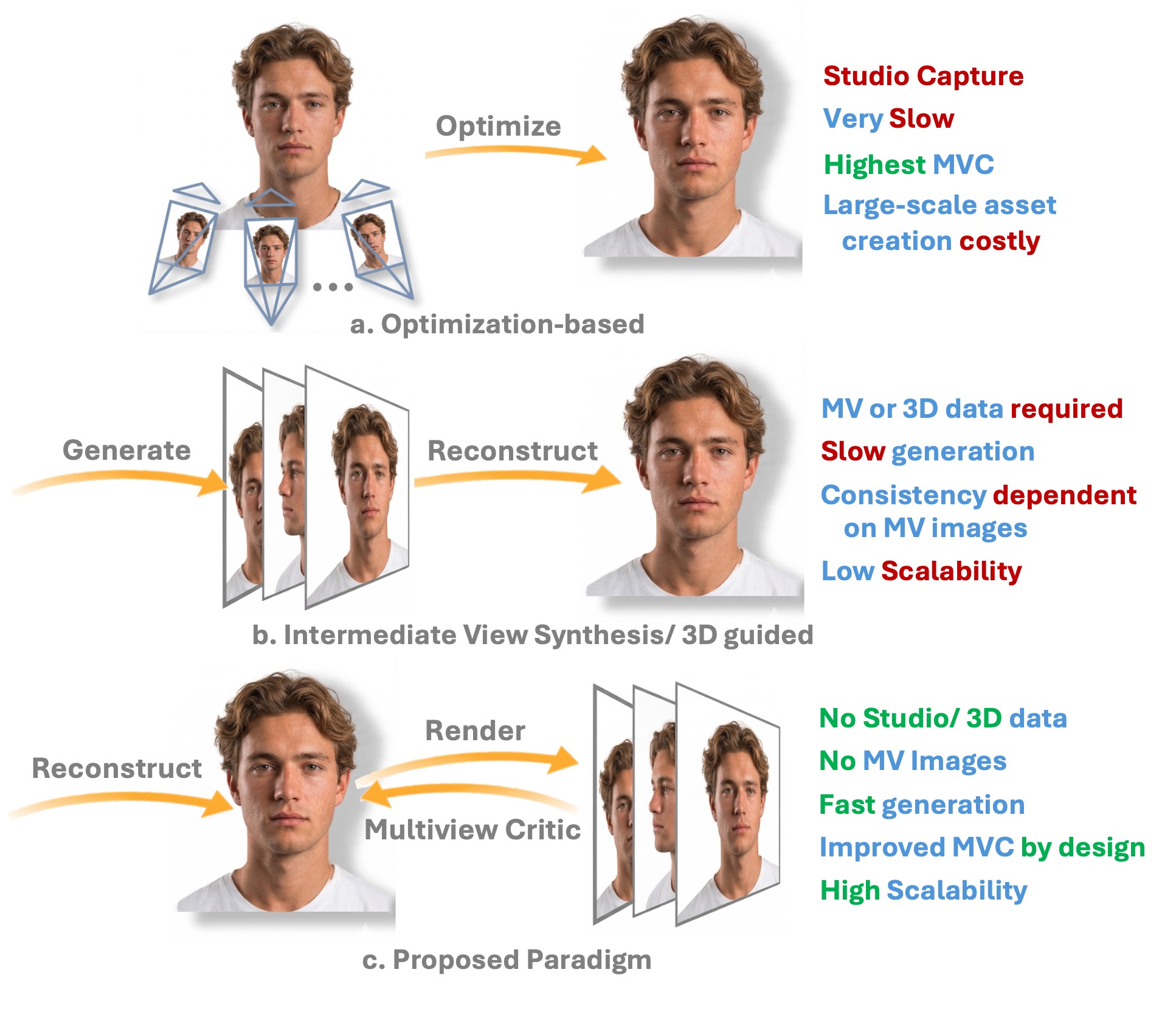
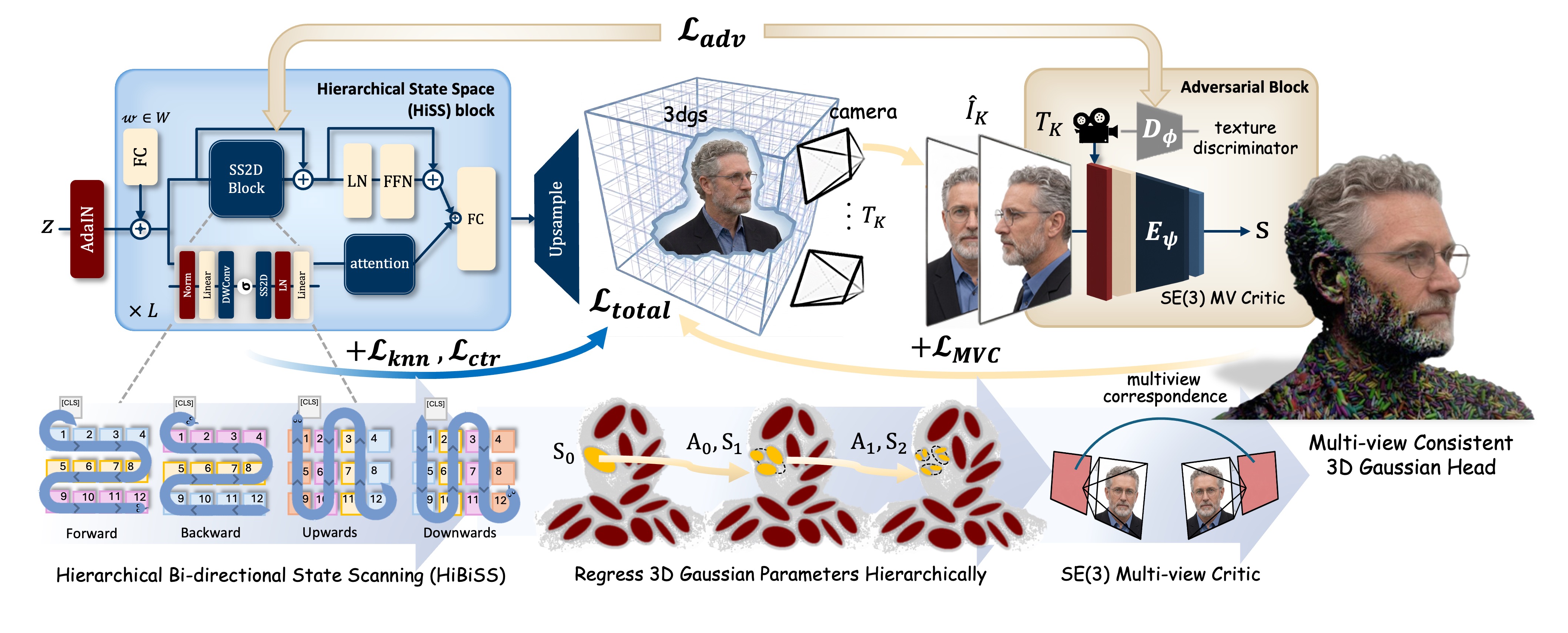
3D Head Avatars from just 70K Random Internet Images! No 3D, no multi-view, no studio, no view synthesis at any stage of training or inference.
1Carnegie Mellon University

TL;DR — High-fidelity, multi-view consistent 3D Gaussian head avatar generation in a minimal resource setting - from 70K images in a real time single forward pass, without any 3D supervision, multi-view captures, studio rigs, or intermediate view synthesis.

Figure 1. The generated Gaussian heads by MVCHead capture complex textures and fine facial micro-structure, including wrinkles, hair wisps, ear rims, lip contours, skin blemishes, eyes, and accessories.
(Hover to magnify.)
3.94
FID on FFHQ-C
SOTA Perceptual Realism
SOTA Perceptual Realism
Real-time
Single-shot
Inference
Inference
240K
Gaussians per Avatar
Fine Facial Micro-structure
Fine Facial Micro-structure
10K
3D Head Assets
FaceGS-10K Dataset
FaceGS-10K Dataset