As extended reality (XR) is redefining how users interact with computing devices, research
in human action recognition
is gaining prominence. Typically, models deployed on immersive computing devices are static
and limited to their default
set of classes.
The goal of our research is to provide users and developers with the capability to
personalize their
experience by adding new action classes to their device models continually. Importantly, a
user should be able to add new classes in a low-shot and efficient manner, while this
process should
not require storing or replaying any of user's sensitive training data. We formalize this
problem as privacy-aware few-shot
continual action recognition.
Towards this end, we propose POET:Prompt Offset Tuning.
While existing prompt tuning approaches have
shown great promise for continual learning of image, text, and video modalities; they demand
access to extensively
pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy
of prompt tuning a
significantly lightweight backbone, pretrained exclusively on the base class data. We
propose a novel spatio-temporal
learnable prompt offset tuning approach, and are the first to apply such prompt tuning to
Graph Neural
Networks.
We contribute two new benchmarks for our new problem setting in human action recognition:
(i) NTU RGB+D
dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition.
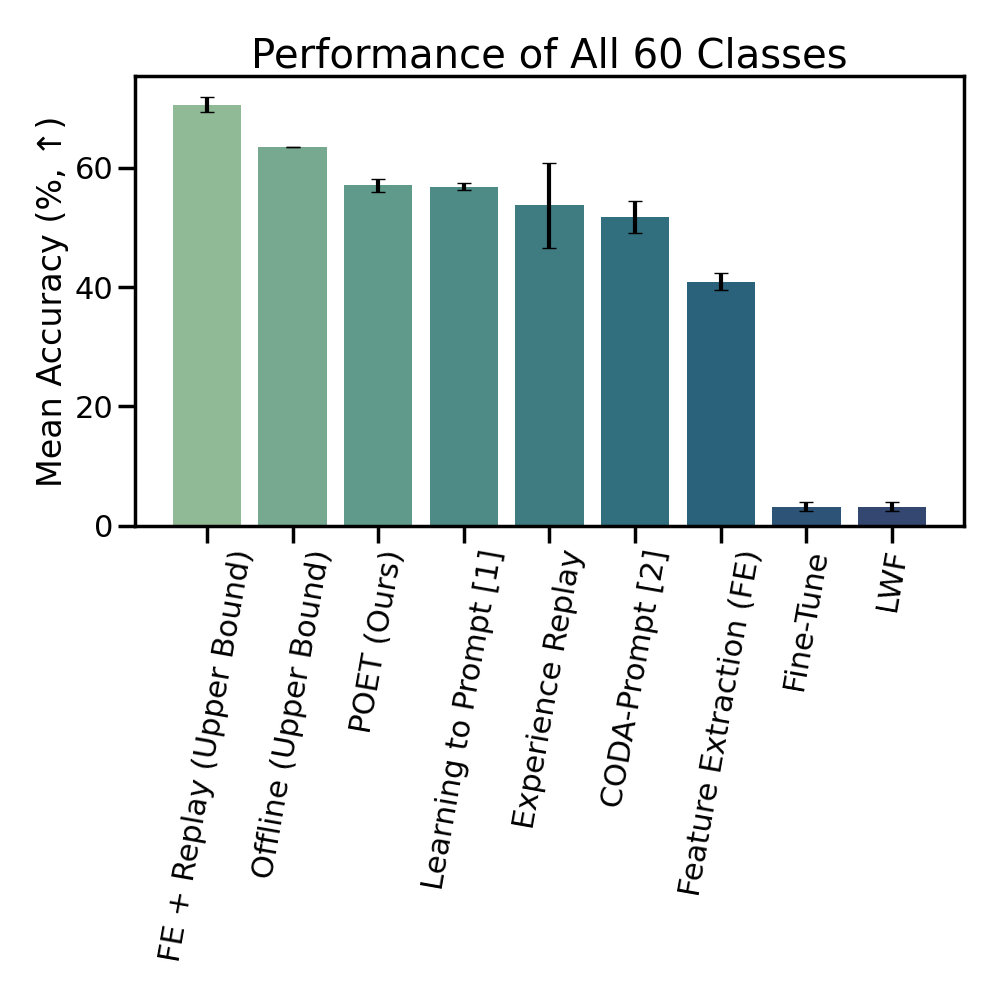
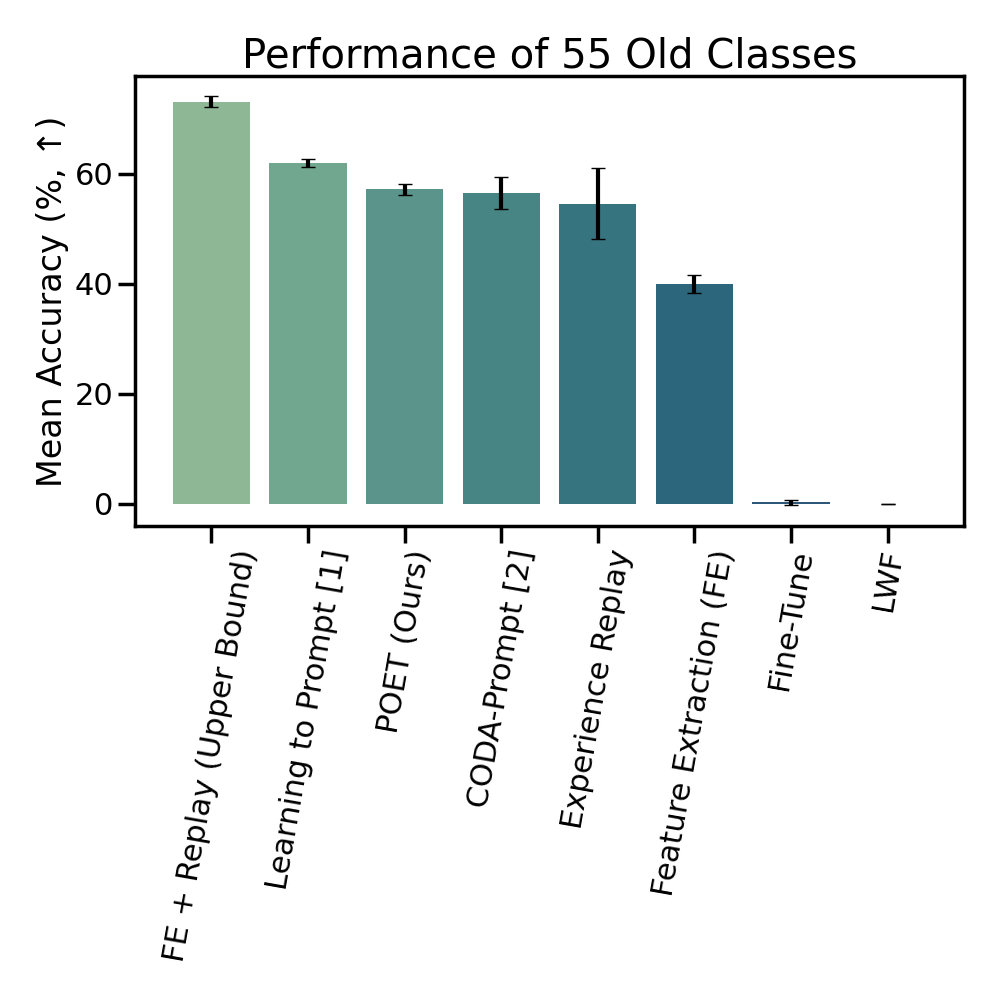
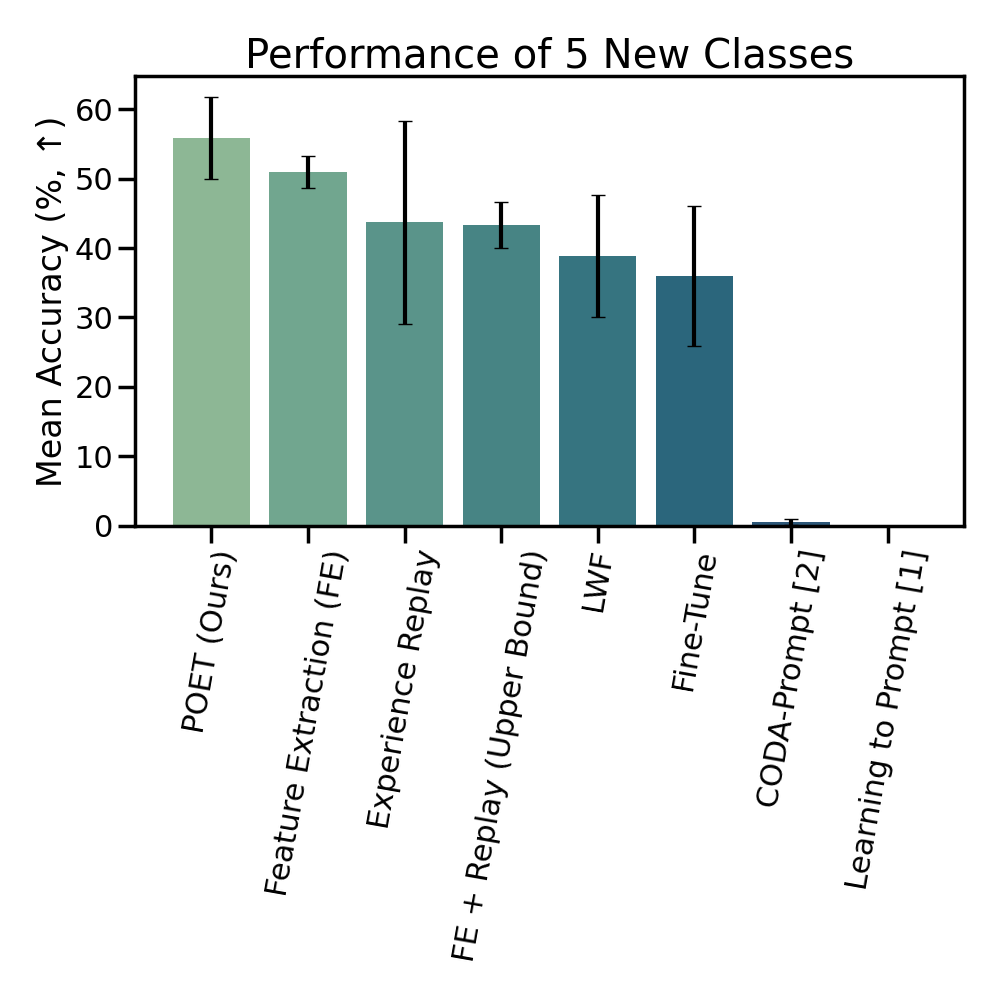
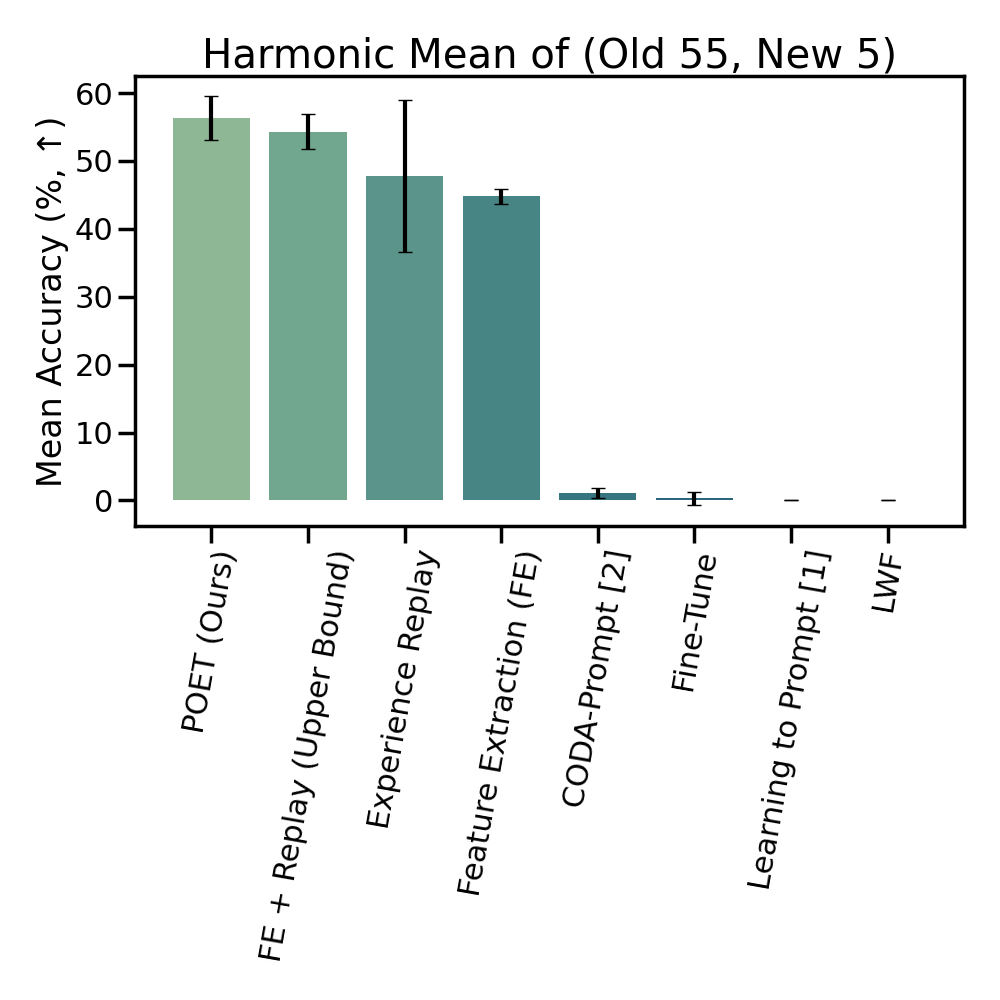
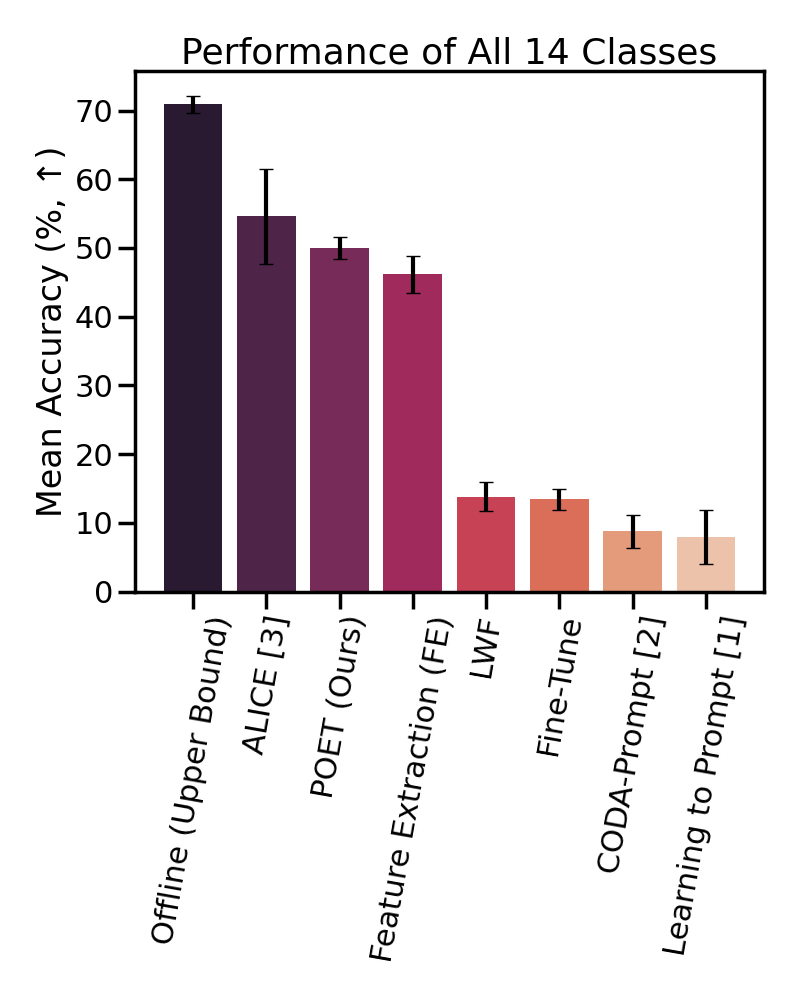
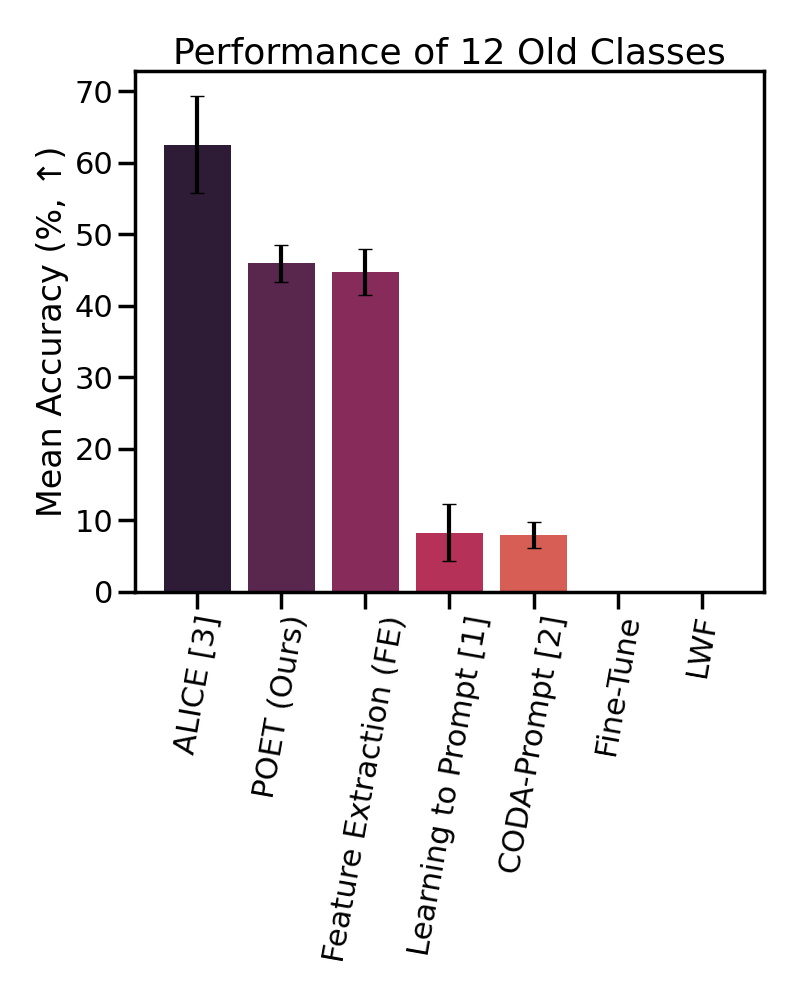
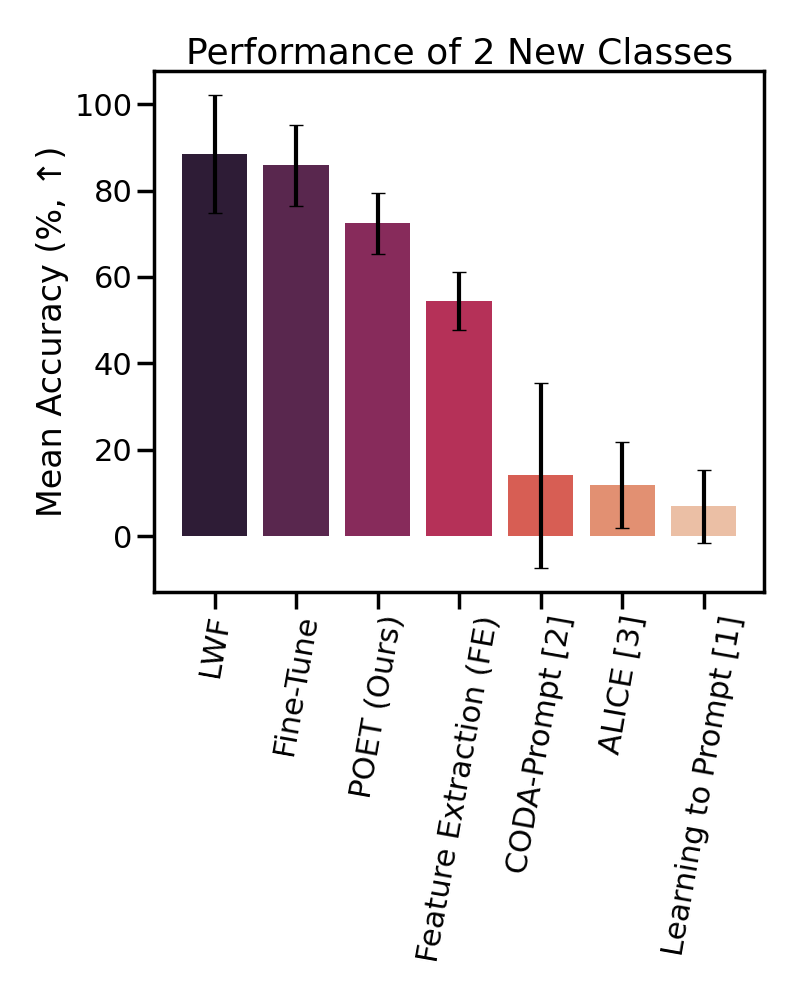
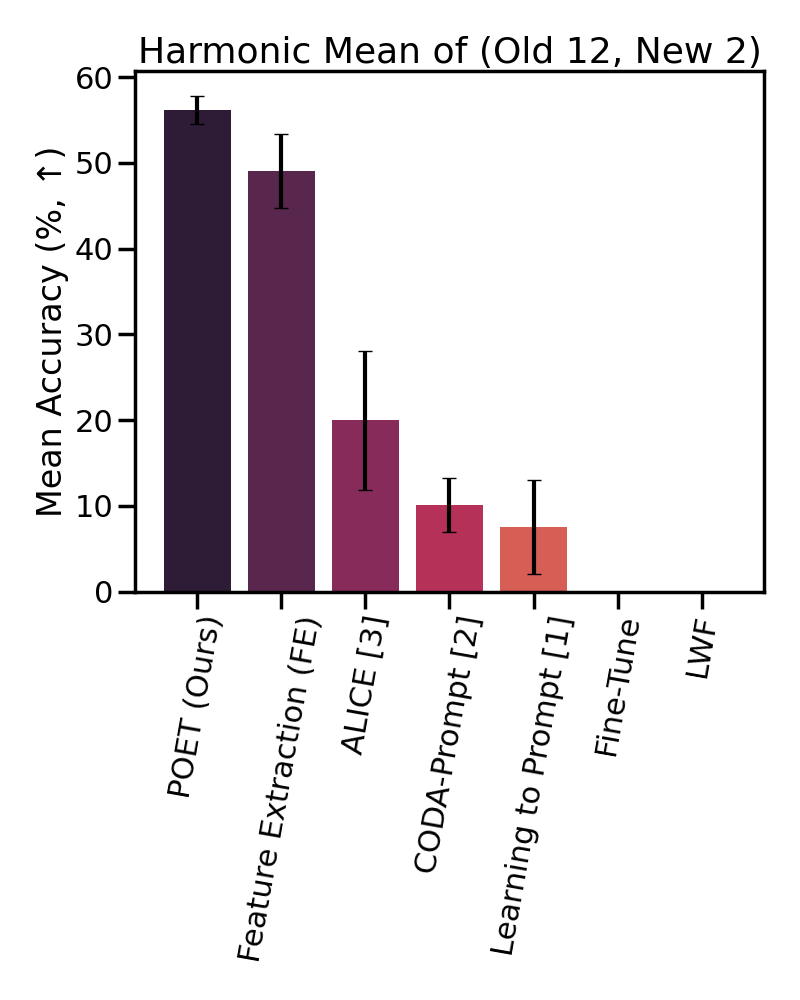
We find that POET
consistently outperforms comprehensive benchmarks.